Case Study 03
Why a NAT Gateway suddenly processed ~10 TB/day
A cloud cost investigation that ended in a networking insight: private does not mean internal.
- AWS
- FinOps
- Kubernetes
- Loki
- Networking
Summary
A NAT Gateway started processing an unexpected amount of traffic. In a short window, volume reached approximately 10 TB/day, creating a cost event that looked like an application or workload issue.
The root cause was different: Loki was reading logs stored in S3, but because the VPC had no S3 Gateway Endpoint, that traffic was routed through the NAT Gateway.
The key lesson: private does not automatically mean internal.
Context
The Kubernetes cluster used Loki as part of its observability stack. Loki stored logs in S3. The bucket was private, access was restricted and application behavior looked correct.
But routing is a separate concern. Without the right VPC endpoint, private subnets still use the NAT Gateway to reach S3.
Visible Problem
The visible signal was cost: NAT Gateway processed bytes jumped to a level that did not match normal application expectations.
Hypothesis 01
Production query spike. A workload might have started pulling a large dataset repeatedly.
Hypothesis 02
Cronjob or batch process. Scheduled jobs might have generated traffic during a specific window.
Hypothesis 03
External integration. A service might have changed behavior and started moving data through NAT.
Investigation Timeline
- Step 1: Confirmed NAT Gateway processed bytes in CloudWatch and scoped the abnormal time window.
- Step 2: Compared the NAT spike with pod-level network metrics in Prometheus.
- Step 3: Isolated Loki querier traffic as the workload matching the spike pattern.
- Step 4: Checked the destination path and found S3 access going through NAT instead of a Gateway Endpoint.
Metrics Correlation
CloudWatch showed the total NAT volume, but not the pod that caused it. Prometheus showed pod-level network receive bytes, but not whether traffic was leaving through NAT. The useful move was correlating both views by time window.
Once NAT processed bytes and Loki pod traffic were aligned, the investigation shifted from application behavior to network routing.
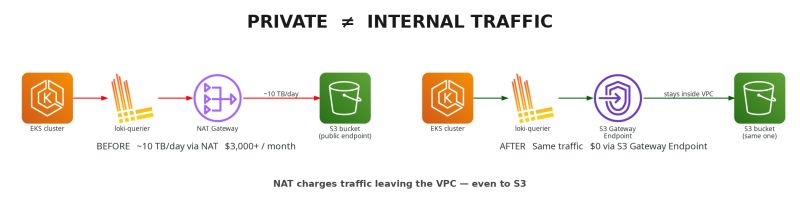
Root Cause
Loki was configured to use S3 as its object store. The configuration was valid. The expensive part was not Loki itself, but the network path from the cluster to S3.
Since the VPC did not have an S3 Gateway Endpoint, requests from private subnets reached S3 through the NAT Gateway. AWS charges NAT Gateway processing per GB, so a heavy log query became a cloud cost event.
Resolution
The fix was adding an S3 Gateway Endpoint to the VPC route tables used by the private subnets. Loki did not need application-level changes. The route changed; the workload kept working.
Operational Impact
Cost path removed
High-volume S3 traffic stopped being processed by the NAT Gateway.
No app rewrite
The workload behavior stayed the same. The infrastructure route changed.
Better investigation pattern
The team gained a method for connecting cloud cost signals with workload-level metrics.
Clearer platform rule
Private AWS services still need explicit private network paths.
Reusable FinOps Pattern
This became a reusable investigation pattern for cloud cost anomalies: start with the billing signal, identify the infrastructure component, correlate with workload metrics and then validate the route table or service endpoint involved.
- CloudWatch for NAT processed bytes.
- Prometheus for pod-level traffic.
- Route tables and VPC endpoints for path validation.
- Known high-volume services such as logs, backups, exports and analytics workloads.
Trade-offs
The fix was simple, but the investigation was not. The main trade-off is operational discipline: VPC endpoints and route tables need to be part of platform design reviews, not added only after costs spike.
Result
- NAT Gateway traffic returned to normal levels.
- The cost path was removed without changing Loki behavior.
- The investigation method became reusable for future FinOps work.
- The team gained a clearer rule: private buckets still need private network paths.
What I Would Improve Next
The next step is not only preventing this exact issue. It is building a repeatable cloud cost investigation runbook: NAT metrics, VPC endpoints, pod-level traffic, route tables and known high-volume services.